入门
- 当您在 IDE 中创建新项目时,大多数 IDE 会为您设置两种不同的构建配置:发布配置和调试配置,开发程序时使用调试构建配置。当您准备好将可执行文件发布给其他人时,或者想要测试性能时,请使用发布构建配置
- Debug:调试版本, 包含调试信息,所以 容量比Release大很多, 并且不进行任何优化(优化会使调试复杂化,因为源代码和生成的指令间关系会更复杂),便于程序员调试
- Release:发布版本, 不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的
对于 CLion 用户,您可以添加 Release:按 Alt+Ctrl+S 调出 Settings > Build,Execution,Deployment > CMake > 单击 Profiles 部分中的 + 按钮,将自动添加 Release 选项
- 禁用编译器扩展以确保您的程序(和编码实践)保持符合 C++ 标准并且可以在任何系统上运行
CLion 使用 CMake 构建项目。
将行 set(CMAKE_CXX_EXTENSIONS OFF) 添加到 CMakeList.txt 以禁用扩展
- 将你的警告级别调到最大,尤其是在你学习的时候。它将帮助您识别可能的问题
在 Clion(从 2021.3 版本开始)中,要将警告级别调到最高,您可以按 Alt+Ctrl+S 调出 Settings ,然后选择 Editor > Inspections > C/C++,然后手动选中所有框,或者在窗口的右侧,在矩形的 severity 框中选择错误,然后在另一个框中选择 In All Scopes
- 选择语言标准:在专业环境中,通常选择比最新标准低一个或两个版本的语言标准(例如,现在 C++20 已经出来了,这意味着 C++14 或 C++17)。这样做通常是为了确保编译器制造商有机会解决缺陷,以便更好地理解新功能的最佳实践。在相关的情况下,这也有助于确保更好的跨平台兼容性,因为某些平台上的编译器可能不会立即为更新的语言标准提供全面支持。启用 C++17 语言标准(或更高版本)后,您应该能够在没有任何警告或错误的情况下编译以下代码
#include <array>
#include <iostream>
#include <string_view>
#include <tuple>
#include <type_traits>
namespace a:🅱️:c
{
inline constexpr std::string_view str{ "hello" };
}
template <class... T>
std::tuple<std::size_t, std::common_type_t<T...>> sum(T... args)
{
return { sizeof...(T), (args + ...) };
}
int main()
{
auto [iNumbers, iSum]{ sum(1, 2, 3) };
std::cout << a:🅱️:c::str << ' ' << iNumbers << ' ' << iSum << '\n';
std::array arr{ 1, 2, 3 };
std::cout << std::size(arr) << '\n';
return 0;
}
C++ 基础知识
注释
写在前面
- 通常,注释应该用于三件事
- 在库、程序或函数级别,使用注释来描述作用
- 在库、程序或函数内部,使用注释来描述如何操作
- 在语句级别,使用注释来描述原因
- 注释是一种很好的方式来提醒自己(或告诉别人)你做出一个决定而不是另一个决定的原因
- 注释您的代码,像在对不知道代码功能的人说话一样写您的注释。不要假设你会记得你为什么做出特定的选择
单行注释
- 在行的右侧添加注释会使代码和注释都难以阅读,尤其是在行很长的情况下。如果行相当短,评论可以简单地对齐(通常是一个制表位),像这样:
std::cout << "Hello world!\n"; // std::cout lives in the iostream library
std::cout << "It is very nice to meet you!\n"; // this is much easier to read
std::cout << "Yeah!\n"; // don't you think so?
- 但是,如果行很长,将注释放在右边会使行变得很长。在这种情况下,单行注释通常放在它正在注释的行之上:
// std::cout lives in the iostream library
std::cout << "Hello world!\n";
// this is much easier to read
std::cout << "It is very nice to meet you!\n";
// don't you think so?
std::cout << "Yeah!\n";
- Commenting out code
// std::cout << 1;
多行注释
- Explaining code
/* This is a multi-line comment.
* the matching asterisks to the left
* can make this easier to read
*/
- Commenting out code
/*
std::cout << 1;
std::cout << 2;
std::cout << 3;
*/
初始化
- Default initialization:默认初始化
int a; // no initializer
- Copy initialization:在现代 C++ 中用的不多
int width = 5; // copy initialization of value 5 into variable width
- Direct initialization:当在括号内提供初始化程序时,这称为直接初始化。最初引入直接初始化是为了更有效地初始化复杂对象。但是,与复制初始化一样,直接初始化在现代 C++ 中使用不多
int width( 5 ); // direct initialization of value 5 into variable width
- Brace initialization:在 C++ 中初始化对象的现代方法是使用一种利用大括号的初始化形式–大括号初始化(也称为统一初始化或列表初始化)。引入大括号初始化是为了提供在大多数情况下都有效的更一致的初始化语法(这就是为什么它有时被称为“统一初始化”)。此外,大括号初始化提供了一种使用值列表初始化对象的方法(这就是为什么它有时被称为“列表初始化”)。大括号初始化有三种形式:
int width { 5 }; // direct brace initialization of value 5 into variable width (preferred)
int height = { 6 }; // copy brace initialization of value 6 into variable height
int depth {}; // value initialization
大括号初始化有一个额外的好处:它不允许“缩小转换”。这意味着如果您尝试使用变量无法安全保存的值来初始化变量,编译器将产生错误,迫使您在继续之前解决这个问题。例如:
int width { 4.5 }; // error: a number with a fractional value can't fit into an int
std::endl vs ‘\n’
使用 std::endl 可能有点低效,因为它实际上做了两个工作:它将光标移动到控制台的下一行,并确保任何缓存的输出立即显示在屏幕上(这称为刷新输出)。当使用 std::cout 将文本写入控制台时,std::cout 通常会刷新输出(如果不刷新,通常也无关紧要),因此让 std::endl 执行刷新很少重要
因此,通常首选使用“\n”字符。 ‘\n’ 字符将光标移动到控制台的下一行,但不请求刷新,因此在刷新不会发生的情况下它会执行得更好。 ‘\n’ 字符也更易于阅读,因为它更短并且可以嵌入到现有文本中
这是一个以两种不同方式使用“\n”的示例:
#include <iostream> // for std::cout
int main()
{
int x{ 5 };
std::cout << "x is equal to: " << x << '\n'; // Using '\n' standalone
std::cout << "And that's all, folks!\n"; // Using '\n' embedded into a double-quoted piece of text (note: no single quotes when used this way)
return 0;
}
这打印:
x is equal to: 5
And that's all, folks!
将文本输出到控制台时,优先使用“\n”而不是 std::endl
代码的可读性
- 您的行的长度不应超过 80 个字符
int main()
{
std::cout << "This is a really, really, really, really, really, really, really, "
"really long line\n"; // one extra indentation for continuation line
std::cout << "This is another really, really, really, really, really, really, really, "
"really long line\n"; // text aligned with the previous line for continuation line
std::cout << "This one is short\n";
}
如果用操作符(例如 « 或 +)拆分长行,则应将操作符放在下一行的开头,而不是当前行的结尾
std::cout << 3 + 4
+ 5 + 6
* 7 * 8;
许多编辑器都有一个内置功能(或插件/扩展),可以在给定的列(例如 80 个字符)处显示一行(称为“列指南”),因此您可以轻松查看行何时变得太长
Clion column guide : File > Settings > Editor > Code Style > General > 在 “Visual guides” 矩形框中键入 80 并应用更改 2. 使用空格通过对齐值或注释或在代码块之间添加间距来使您的代码更易于阅读
cost = 57;
pricePerItem = 24;
value = 5;
numberOfItems = 17;
std::cout << "Hello world!\n"; // cout lives in the iostream library
std::cout << "It is very nice to meet you!\n"; // these comments are easier to read
std::cout << "Yeah!\n"; // especially when all lined up
// cout lives in the iostream library
std::cout << "Hello world!\n";
// these comments are easier to read
std::cout << "It is very nice to meet you!\n";
// when separated by whitespace
std::cout << "Yeah!\n";
C++ 基础:函数和文件
函数返回值
C++标准只定义了3种状态码的含义:0、EXIT_SUCCESS、EXIT_FAILURE。 0 和 EXIT_SUCCESS 都表示程序执行成功。 EXIT_FAILURE 表示程序没有成功执行
EXIT_SUCCESS 和 EXIT_FAILURE 是 <cstdlib> 标头中定义的预处理器宏:
#include <cstdlib> // for EXIT_SUCCESS and EXIT_FAILURE
int main()
{
return EXIT_SUCCESS;
}
如果你想最大限度地提高可移植性,你应该只使用 0 或 EXIT_SUCCESS 来指示成功终止,或者使用 EXIT_FAILURE 来指示不成功终止
前向声明和定义
对于以下每个程序,说明它们是编译失败、链接失败、两者都失败,还是编译和链接成功。如果您不确定,请尝试编译它们!
#include <iostream>
int add(int x, int y);
int main()
{
std::cout << "3 + 4 + 5 = " << add(3, 4, 5) << '\n';
return 0;
}
int add(int x, int y)
{
return x + y;
}
Doesn’t compile. The compiler will complain that the add() called in main() does not have the same number of parameters as the one that was forward declared.
#include <iostream>
int add(int x, int y);
int main()
{
std::cout << "3 + 4 + 5 = " << add(3, 4, 5) << '\n';
return 0;
}
int add(int x, int y, int z)
{
return x + y + z;
}
Doesn’t compile. The compiler will complain that it can’t find a matching add() function that takes 3 arguments, because the add() function that was forward declared only takes 2 arguments.
#include <iostream>
int add(int x, int y);
int main()
{
std::cout << "3 + 4 = " << add(3, 4) << '\n';
return 0;
}
int add(int x, int y, int z)
{
return x + y + z;
}
Doesn’t link. The compiler will match the forward declaration of add to the function call to add() in main(). However, no add() function that takes two parameters was ever implemented (we only implemented one that took 3 parameters), so the linker will complain.
#include <iostream>
int add(int x, int y, int z);
int main()
{
std::cout << "3 + 4 + 5 = " << add(3, 4, 5) << '\n';
return 0;
}
int add(int x, int y, int z)
{
return x + y + z;
}
Compiles and links. The function call to add() matches the forward declaration, the implemented function also matches.
具有多个cpp文件的程序
.cpp 文件
编译器会单独编译每个文件。它不知道其他代码文件的内容,也不记得它从以前编译的代码文件中看到的任何内容。这种有限的可见性和短内存是有意的,因此文件可能具有名称相同的函数或变量而不会相互冲突。
C++ 语言支持"分别编译"(separatecompilation)。也就是说,一个程序所有的内容,可以分成不同的部分分别放在不同的 .cpp 文件里。.cpp 文件里的东西都是相对独立的,在编译(compile)时不需要与其他文件互通,只需要在编译成目标文件后再与其他的目标文件做一次链接(link)就行了。比如,在文件 a.cpp 中定义了一个全局函数 “void a(){}",而在文件 b.cpp 中需要调用这个函数。即使这样,文件 a.cpp 和文件 b.cpp 并不需要相互知道对方的存在,而是可以分别地对它们进行编译,编译成目标文件之后再链接,整个程序就可以运行了
这是怎么实现的呢?从写程序的角度来讲,很简单。在文件 b.cpp 中,在调用 “void a()” 函数之前,先声明一下这个函数 “voida();",就可以了。这是因为编译器在编译 b.cpp 的时候会生成一个符号表(symbol table),像 “void a()” 这样的看不到定义的符号,就会被存放在这个表中。再进行链接的时候,编译器就会在别的目标文件中去寻找这个符号的定义。一旦找到了,程序也就可以顺利地生成了
.h 文件
考虑一下,如果有一个很常用的函数 “void f() {}",在整个程序中的许多 .cpp 文件中都会被调用,那么,我们就只需要在一个文件中定义这个函数,而在其他的文件中声明这个函数就可以了。一个函数还好对付,声明起来也就一句话。但是,如果函数多了,比如是一大堆的数学函数,有好几百个,那怎么办?
头文件允许我们将声明放在一个位置,然后在我们需要的地方导入它们。这可以在多文件程序中节省大量的输入
头文件通常只包含函数和变量声明,而不包含函数和变量定义(否则可能会导致违反单一定义规则)。符号常量是一个例外
使用双引号 "" 包括您编写的或预期在当前目录中找到的头文件
使用尖括号 <> 来包含编译器、操作系统或您在系统其他位置安装的第三方库附带的标头
为什么 iostream 没有 .h 扩展名?
首次创建 C++ 时,标准库中的所有文件都以 .h 后缀结尾。生活是一致的,而且很好。 cout 和 cin 的原始版本在 iostream.h 中声明。当 ANSI 委员会对该语言进行标准化时,他们决定将标准库中使用的所有名称移动到 std 命名空间中,以帮助避免与用户定义的标识符发生命名冲突。然而,这带来了一个问题:如果他们将所有名称移动到 std 名称空间中,那么旧程序(包括 iostream.h)将不再工作!
为解决此问题,引入了一组缺少 .h 扩展名的新头文件。这些新的头文件定义了 std 命名空间内的所有名称。这样,包含 #include <iostream.h> 的旧程序不需要重写,新程序可以 #include <iostream>
Include来自其他目录的头文件
一种(不好的)方法是在#include 行中包含一个指向您要包含的头文件的相对路径。例如:
#include "headers/myHeader.h"
#include "../moreHeaders/myOtherHeader.h"
虽然这会编译(假设文件存在于那些相对目录中),但这种方法的缺点是它需要您在代码中反映您的目录结构。如果您更新了目录结构,您的代码将不再有效
更好的方法是告诉你的编译器或 IDE 你在其他位置有一堆头文件,这样当它在当前目录中找不到它们时就会去那里寻找。这通常可以通过在 IDE 项目设置中设置包含路径或搜索目录来完成
这种方法的好处是,如果您更改了目录结构,您只需更改一个编译器或 IDE 设置,而不是每个代码文件
Headers may include other headers
当您的代码文件 #includes 第一个头文件时,您还将获得第一个头文件包含的任何其他头文件(以及那些包含的任何头文件,等等)。这些额外的头文件有时称为传递包含,因为它们是隐式包含而不是显式包含
每个文件都应该 显式#include 它需要编译的所有头文件。不要依赖从其他标头传递过来的标头
include 头文件顺序
如果你的头文件写得正确并且#include了他们需要的一切,那么包含的顺序应该无关紧要
现在考虑以下场景:假设 header A 需要 header B 的声明,但忘记包含它。在我们的代码文件中,如果我们在 header A 之前包含 header B,我们的代码仍然可以编译!这是因为编译器会先编译 B 中的所有声明,然后再编译 A 中依赖于这些声明的代码
但是,如果我们首先包含 header A,那么编译器会报错,因为 A 的代码将在编译器看到 B 的声明之前编译。这实际上是更可取的,因为错误已经浮出水面,然后我们可以修复它.
为了最大限度地提高编译器标记缺少包含的机会,请按以下方式命令您的#includes:
- The paired header file
- Other headers from your project
- 3rd party library headers
- Standard library headers
The headers for each grouping should be sorted alphabetically(按字母顺序排序).
这样,如果您的某个用户定义的 Header 缺少第 3 方库或标准库 Header 的#include,则更有可能导致编译错误,因此您可以修复它
Header file best practices
- 始终 include header guards
- 不要在头文件中定义变量和函数(全局常量是一个例外)
- 为头文件指定与其关联的源文件相同的名称(例如,grades.h 与 grades.cpp 配对)
- 每个头文件应该有一个特定的工作,并且尽可能独立。例如,您可以将与功能 A 相关的所有声明放在 A.h 中,将与功能 B 相关的所有声明放在 B.h 中。这样如果你以后只关心 A,你可以只 include A.h 而不会得到任何与 B 相关的东西
- 请注意您需要为代码文件中使用的功能显式包含哪些 header
- 您编写的每个 header 都应该自行编译(它应该
#include它需要的每个依赖项) - 仅
#include您需要的内容(不要仅仅因为可以就包含所有内容) - 不要
#include.cpp 文件
Header guards
使用头文件,很容易导致头文件中的定义被多次包含的情况。当一个头文件 #includes 另一个头文件(这很常见)时,就会发生重复定义
Example:
square.h:
// We shouldn't be including function definitions in header files
// But for the sake of this example, we will
int getSquareSides()
{
return 4;
}
geometry.h:
#include "square.h"
main.cpp:
#include "square.h"
#include "geometry.h"
int main()
{
return 0;
}
在预处理完所有 #includes 之后,main.cpp 最终看起来像这样:
int getSquareSides() // from square.h
{
return 4;
}
int getSquareSides() // from geometry.h (via square.h)
{
return 4;
}
int main()
{
return 0;
}
我们可以通过一种称为 Header guards 的机制来避免上述问题。Header guards 是采用以下形式的条件编译指令:
#ifndef SOME_UNIQUE_NAME_HERE
#define SOME_UNIQUE_NAME_HERE
// your declarations (and certain types of definitions) here
#endif
当此标头为#included 时,预处理器会检查之前是否定义了 SOME_UNIQUE_NAME_HERE。如果这是我们第一次包含此标头,则不会定义 SOME_UNIQUE_NAME_HERE。因此,它 #defines SOME_UNIQUE_NAME_HERE 并包含文件的内容。如果标头再次包含到同一个文件中,SOME_UNIQUE_NAME_HERE 将在第一次包含标头的内容时已经定义,并且标头的内容将被忽略
你所有的头文件都应该有头文件保护。 SOME_UNIQUE_NAME_HERE 可以是您想要的任何名称,但按照惯例设置为头文件的完整文件名,全部大写,使用下划线作为空格或标点符号
在大型程序中,可能有两个单独的头文件(包含在不同的目录中)最终具有相同的文件名(例如 directoryA\config.h 和 directoryB\config.h)。如果仅文件名用于包含保护(例如 CONFIG_H),这两个文件最终可能会使用相同的保护名称。如果发生这种情况,任何包含(直接或间接)这两个 config.h 文件的文件将不会收到要包含的包含文件的内容。这可能会导致编译错误
由于这种保护名称冲突的可能性,许多开发人员建议在标头保护中使用更复杂/唯一的名称。一些好的建议是 <PROJECT>_<PATH>_<FILE>_H 、<FILE>_<LARGE RANDOM NUMBER>_H 或 <FILE>_<CREATION DATE>_H 的命名约定
Summary
标头保护旨在确保给定标头文件的内容不会被多次复制到任何单个文件中,以防止重复定义
请注意,重复声明是可以的,因为一个声明可以多次声明而不会发生意外——但即使您的头文件由所有声明(无定义)组成,包含头文件保护仍然是 Best Practice
Note that header guards do not prevent the contents of a header file from being copied (once) into separate project files. This is a good thing, because we often need to reference the contents of a given header from different project files
pragma once
现代编译器使用 #pragma 指令支持一种更简单的替代形式的标头保护:
#pragma once
// your code here
#pragma once 与标头保护具有相同的目的,并且具有更短且不易出错的额外好处。对于大多数项目,#pragma once 工作正常,许多开发人员更喜欢使用它们而不是标头保护。然而,#pragma once 并不是 C++ 语言的正式部分(而且可能永远不会是,因为它无法以在所有情况下都可靠工作的方式实现)
为了最大的可移植性,优先使用 header guards 而不是 #pragma once
命名冲突和命名空间介绍
命名冲突
大多数命名冲突发生在两种情况下:
两个(或更多)同名函数(或全局变量)被引入到属于同一程序的不同文件中。这将导致链接器错误
两个(或更多)同名函数(或全局变量)被引入到同一个文件中。这将导致编译器错误
命名空间
命名空间是一个区域,允许您在其中声明名称以消除歧义。命名空间为在其中声明的名称提供一个作用域区域(称为命名空间作用域)——这仅仅意味着在命名空间内声明的任何名称都不会被误认为是其他作用域中的相同名称
命名空间通常用于对大型项目中的相关标识符进行分组,以帮助确保它们不会无意中与其他标识符发生冲突。例如,如果您将所有数学函数放在一个名为 math 的命名空间中,那么您的数学函数将不会与 math 命名空间之外的同名函数发生冲突
在 C++ 中,任何未在类、函数或命名空间内定义的名称都被视为隐式定义的命名空间的一部分,称为全局命名空间(有时也称为全局范围)
只有声明和定义语句可以出现在全局命名空间中。这意味着我们可以在全局命名空间中定义变量,尽管通常应该避免这种情况。这也意味着其他类型的语句(例如表达式语句)不能放在全局命名空间中(全局变量的初始化器是一个例外):
#include <iostream> // handled by preprocessor
// All of the following statements are part of the global namespace
void foo(); // okay: function forward declaration in the global namespace
int x; // compiles but strongly discouraged: uninitialized variable definition in the global namespace
int y { 5 }; // compiles but discouraged: variable definition with initializer in the global namespace
x = 5; // compile error: executable statements are not allowed in the global namespace
int main() // okay: function definition in the global namespace
{
return 0;
}
void goo(); // okay: another function forward declaration in the global namespace
在最初设计 C++ 时,C++ 标准库中的所有标识符(包括 std::cin 和 std::cout)都可以在没有 std:: 前缀的情况下使用(它们是全局命名空间的一部分)。但是,这意味着标准库中的任何标识符都可能与您为自己的标识符选择的任何名称(也在全局命名空间中定义)发生冲突。当您#include 标准库中的新文件时,正在运行的代码可能会突然出现命名冲突。或者更糟的是,在一个版本的 C++ 下编译的程序可能无法在未来的 C++ 版本下编译,因为引入标准库的新标识符可能与已经编写的代码发生命名冲突。因此,C++ 将标准库中的所有功能移动到名为“std”(标准的缩写)的命名空间中
std::cout 的名字并不是真正的 std::cout。它实际上只是 cout,而 std 是标识符 cout 所属的命名空间的名称。因为 cout 是在 std 命名空间中定义的,所以名称 cout 不会与我们在全局命名空间中创建的任何名为 cout 的对象或函数发生冲突
预处理器简介
在编译之前,代码文件会经历一个称为翻译的阶段。翻译阶段会发生很多事情,让您的代码准备好进行编译(如果您好奇,可以在此处找到翻译阶段列表)。应用了翻译的代码文件称为翻译单元
最值得注意的翻译阶段涉及预处理器。预处理器最好被认为是一个单独的程序,它可以处理每个代码文件中的文本
当预处理器运行时,它会扫描代码文件(从上到下),寻找预处理器指令。预处理程序指令(通常简称为 指令(Directives))是以# 符号开头并以换行符(不是分号)结尾的指令。这些指令告诉预处理器执行某些文本操作任务。请注意,预处理器不理解 C++ 语法——相反,指令有自己的语法(在某些情况下类似于 C++ 语法,而在其他情况下,则不太相似)
请注意,预处理器不会以任何方式修改原始代码文件——相反,预处理器所做的所有文本更改都会在每次编译代码文件时临时发生在内存中或使用临时文件
Includes
当您 #include 一个文件时,预处理器会用 include 文件的内容替换 #include 指令。然后对 include 的内容进行预处理(连同文件的其余部分),然后进行编译
Macro defines
#define 指令可用于创建 宏
有两种基本类型的宏:类对象宏和类函数宏
类函数宏的行为类似于函数,并且具有相似的目的。它们的使用通常被认为是危险的,它们几乎可以做的任何事情都可以通过一个正常的函数来完成
类对象宏可以通过以下两种方式之一定义:
#define identifier
#define identifier substitution_text
替换文本的类对象宏被用作(在 C 中)将名称分配给文字的一种方式。这不再是必需的,因为 C++ 中提供了更好的方法(Const 变量和符号常量)。带有替换文本的类对象宏现在通常只能在遗留代码中看到
没有替换文本的类对象宏:标识符的任何进一步出现都将被删除并被替换为任何东西!
与带有替换文本的类对象宏不同,这种形式的宏通常被认为可以使用。
Conditional compilation
条件编译预处理器指令允许您指定在什么条件下编译或不编译。有很多不同的条件编译指令,但我们在这里只介绍目前使用最多的三个:#ifdef、#ifndef 和 #endif
#ifdef 预处理器指令允许预处理器检查标识符是否先前已被#defined。如果是,编译 #ifdef 和匹配的 #endif 之间的代码。如果不是,代码将被忽略
考虑以下程序:
#include <iostream>
#define PRINT_JOE
int main()
{
#ifdef PRINT_JOE
std::cout << "Joe\n"; // will be compiled since PRINT_JOE is defined
#endif
#ifdef PRINT_BOB
std::cout << "Bob\n"; // will be ignored since PRINT_BOB is not defined
#endif
return 0;
}
因为 PRINT_JOE 已被 #defined,std::cout << "Joe\n" 行将被编译。因为 PRINT_BOB 尚未被 #defined,std::cout << "Bob\n" 行将被忽略
#ifndef 与 #ifdef 相反,因为它允许您检查标识符是否尚未 #defined
#include <iostream>
int main()
{
#ifndef PRINT_BOB
std::cout << "Bob\n";
#endif
return 0;
}
该程序打印 “Bob”,因为 PRINT_BOB 从未被 #defined
条件编译的一个更常见的用途是使用 #if 0 将代码块排除在编译之外(就像它在注释块中一样):
#include <iostream>
int main()
{
std::cout << "Joe\n";
#if 0 // Don't compile anything starting here
std::cout << "Bob\n";
std::cout << "Steve\n";
#endif // until this point
return 0;
}
这也提供了一种方便的方法来**“注释掉”包含多行注释的代码**(由于多行注释是不可嵌套的,因此不能使用另一个多行注释来注释掉):
#include <iostream>
int main()
{
std::cout << "Joe\n";
#if 0 // Don't compile anything starting here
std::cout << "Bob\n";
/* Some
* multi-line
* comment here
*/
std::cout << "Steve\n";
#endif // until this point
return 0;
}
类对象宏不影响其他预处理器指令,宏只会导致普通代码的文本替换。其他预处理器命令将被忽略
#define FOO 9 // Here's a macro substitution
#ifdef FOO // This FOO does not get replaced because it’s part of another preprocessor directive
std::cout << FOO; // This FOO gets replaced with 9 because it's part of the normal code
#endif
指令在编译前解析,逐个文件地从上到下解析
#include <iostream>
void foo()
{
#define MY_NAME "Alex"
}
int main()
{
std::cout << "My name is: " << MY_NAME;
return 0;
}
即使看起来 #define MY_NAME “Alex” 是在函数 foo 中定义的,预处理器也不会注意到,因为它不理解像函数这样的 C++ 概念。因此,该程序的行为与 #define MY_NAME “Alex” 在函数 foo 之前或之后立即定义的程序相同。为了一般的可读性,您通常希望在函数之外 #define 标识符
预处理器完成后,该文件中所有定义的标识符都将被丢弃。这意味着指令仅从定义点到定义它们的文件末尾有效。一个代码文件中定义的指令不会影响同一项目中的其他代码文件
考虑以下示例:
function.cpp:
#include <iostream>
void doSomething()
{
#ifdef PRINT
std::cout << "Printing!";
#endif
#ifndef PRINT
std::cout << "Not printing!";
#endif
}
main.cpp:
void doSomething(); // forward declaration for function doSomething()
#define PRINT
int main()
{
doSomething();
return 0;
}
上面的程序会打印:
Not printing!
尽管 PRINT 是在 main.cpp 中定义的,但这对 function.cpp 中的任何代码都没有任何影响(PRINT 只是从定义点到 main.cpp 末尾的 #defined)
如何完成你的第一个程序
- Design(设计)
- 定义目标。将此表示为面向用户的结果通常很有用,例如:
- 允许用户组织姓名和相关电话号码的列表
- 模拟球从塔上掉落到地面需要多长时间
- 定义需求。既指您的解决方案需要遵守的约束(例如预算、时间线、空间、内存等),也指程序为满足用户需求而必须展示的能力。请注意,您的要求同样应该关注“什么”,而不是“如何”。例如:
- 应保存电话号码,以便日后调用
- 用户应该能够输入塔的高度
- 定义您的工具、目标和备份计划
- 定义您的程序将运行的目标架构 和/或 操作系统
- 确定您将使用的工具集
- 确定您是单独编写程序还是作为团队的一部分编写程序’
- 定义您的测试/反馈/发布策略
- 确定您将如何备份您的代码
- 将困难问题分解为简单问题。如果发现其中一个项目(功能)太难实现,只需将该项目拆分为多个子项目/子功能。最终,您应该达到程序中的每个功能都可以轻松实现的地步
- 弄清楚事件的顺序
- 定义目标。将此表示为面向用户的结果通常很有用,例如:
- Implementation(实现)
- 概述您的主要功能。
int main() { // Get first number from user // getUserInput(); // Get mathematical operation from user // getMathematicalOperation(); // Get second number from user // getUserInput(); // Calculate result // calculateResult(); // Print result // printResult(); return 0; }- 实现各个功能。对于每个函数,您将做三件事:
- 定义函数原型(输入和输出)
- 编写函数
- 测试功能
- 最终测试。一旦你的程序“完成”,最后一步就是测试整个程序并确保它按预期工作。如果它不起作用,请修复它
- Words of advice when writing programs(忠告)
- Keep your programs simple to start.让你的第一个目标尽可能简单,一些你绝对可以实现的目标
- Add features over time.一旦您的简单程序运行良好并且运行良好,您就可以向其添加功能
- Focus on one area at a time.不要试图一次编写所有代码,也不要将注意力分散到多个任务上。一次专注于一项任务
- Test each piece of code as you go.编写一段代码,然后立即编译并测试它。如果它不起作用,您将确切地知道问题出在哪里,并且很容易修复。确定代码有效后,移至下一段并重复。完成代码的编写可能需要更长的时间,但是当您完成后,整个事情应该可以正常工作,并且您不必花费两倍的时间来弄清楚为什么它不起作用
- Don’t invest in perfecting early code.让你的功能最低限度地工作,然后继续。不要以完美为目标——重要的程序从来都不是完美的,而且总有更多的事情可以做来改进它们。达到“足够好”并继续前进
调试 C++ 程序
调试过程
- 找到问题的根本原因(通常是不起作用的代码行)
- 确保您了解问题发生的原因
- 确定您将如何解决问题
- 修复问题
- 重新测试以确保问题已解决并且没有出现新问题
调试策略
观察程序运行时的行为,并尝试从中诊断问题
- 弄清楚如何重现问题
- 运行程序并收集信息以缩小问题所在的范围
- 重复前面的步骤,直到找到问题
调试策略 1:注释掉你的代码
如果您的程序表现出错误行为,减少必须搜索的代码量的一种方法是注释掉一些代码并查看问题是否仍然存在。如果问题仍然存在,则注释掉的代码不负责任
调试策略 2:验证代码流
另一个在更复杂的程序中常见的问题是程序调用一个函数的次数太多或太少(包括根本不调用)
在这种情况下,将语句放在函数的顶部以打印函数的名称会很有帮助。这样,当程序运行时,您可以看到调用了哪些函数
当出于调试目的打印信息时,使用 std::cerr 而不是 std::cout。这样做的一个原因是 std::cout 可能被缓冲,这意味着在您要求 std::cout 输出信息和它实际输出信息之间可能会有一个暂停。如果您使用 std::cout 进行输出,然后您的程序随后立即崩溃,则 std::cout 可能已经或可能还没有实际输出。这可能会误导您了解问题出在哪里。另一方面,std::cerr 是无缓冲1的,这意味着您发送给它的任何内容都会立即输出。这有助于确保所有调试输出尽快出现(以一些性能为代价,我们在调试时通常不关心)
使用 std::cerr 还有助于明确输出的信息是针对错误情况而不是正常情况
添加临时调试语句时,不缩进它们会很有帮助。这使它们更容易在以后找到并移除
#include <iostream>
int getValue()
{
std::cerr << "getValue() called\n";
return 4;
}
int main()
{
std::cerr << "main() called\n";
std::cout << getValue;
return 0;
}
调试策略 3:打印值
对于某些类型的错误,程序可能会计算或传递错误的值。
我们还可以输出变量(包括参数)或表达式的值,以确保它们是正确的。
For example:
#include <iostream>
int add(int x, int y)
{
std::cerr << "add() called (x=" << x <<", y=" << y << ")\n";
return x + y;
}
void printResult(int z)
{
std::cout << "The answer is: " << z << '\n';
}
int getUserInput()
{
std::cout << "Enter a number: ";
int x{};
std::cin >> x;
return x;
}
int main()
{
int x{ getUserInput() };
std::cerr << "main::x = " << x << '\n';
int y{ getUserInput() };
std::cerr << "main::y = " << y << '\n';
std::cout << x << " + " << y << '\n';
int z{ add(x, 5) };
std::cerr << "main::z = " << z << '\n';
printResult(z);
return 0;
}
现在我们将得到输出:
Enter a number: 4
main::x = 4
Enter a number: 3
main::y = 3
add() called (x=4, y=5)
main::z = 9
The answer is: 9
虽然为诊断目的向程序添加调试语句是一种常见的基本技术,也是一种功能性技术(尤其是当调试器由于某种原因不可用时),但由于多种原因它并不是很好:
- 调试语句使您的代码混乱。
- 调试语句使程序的输出混乱。
- 调试语句必须在完成后删除,这使得它们不可重用。
- 调试语句需要修改您的代码以添加和删除,这可能会引入新的错误。
条件化调试代码
一种更容易在整个程序中禁用和启用调试的方法是使用预处理器指令使调试语句有条件:
#include <iostream>
#define ENABLE_DEBUG // comment out to disable debugging
int getUserInput()
{
#ifdef ENABLE_DEBUG
std::cerr << "getUserInput() called\n";
#endif
std::cout << "Enter a number: ";
int x{};
std::cin >> x;
return x;
}
int main()
{
#ifdef ENABLE_DEBUG
std::cerr << "main() called\n";
#endif
int x{ getUserInput() };
std::cout << "You entered: " << x;
return 0;
}
现在我们可以通过注释/取消注释#define ENABLE_DEBUG 来启用调试。这使我们能够重用以前添加的调试语句,然后在用完它们后将它们禁用,而不必从代码中实际删除它们
这解决了必须删除调试语句的问题以及这样做的风险,但代价是代码更加混乱。这种方法的另一个缺点是,如果您输入错误(例如拼错“DEBUG”)或忘记将标头包含到代码文件中,则可能无法启用该文件的部分或全部调试
使用日志
通过预处理器进行条件化调试的另一种方法是将调试信息发送到日志文件。日志文件是记录软件中发生的事件的文件(通常存储在磁盘上)。将信息写入日志文件的过程称为日志记录。大多数应用程序和操作系统都会写入可用于帮助诊断发生的问题的日志文件
日志文件有几个优点。因为写入日志文件的信息与程序的输出是分开的,所以可以避免将正常输出和调试输出混合在一起造成的混乱。日志文件也可以很容易地发送给其他人进行诊断——所以如果有人使用你的软件有问题,你可以让他们把日志文件发给你,这可能会帮助你找到问题所在的线索
虽然您可以编写自己的代码来创建日志文件并将输出发送给它们,但最好还是使用许多现有的第三方日志记录工具之一
Using the plog logger:
#include <iostream>
#include <plog/Log.h> // Step 1: include the logger headers
#include <plog/Initializers/RollingFileInitializer.h>
int getUserInput()
{
PLOGD << "getUserInput() called"; // PLOGD is defined by the plog library
std::cout << "Enter a number: ";
int x{};
std::cin >> x;
return x;
}
int main()
{
plog::init(plog::debug, "Logfile.txt"); // Step 2: initialize the logger
PLOGD << "main() called"; // Step 3: Output to the log as if you were writing to the console
int x{ getUserInput() };
std::cout << "You entered: " << x;
return 0;
}
这是上述记录器的输出(在 Logfile.txt 文件中):
2018-12-26 20:03:33.295 DEBUG [4752] [main@14] main() called
2018-12-26 20:03:33.296 DEBUG [4752] [getUserInput@4] getUserInput() called
您如何包含、初始化和使用记录器将根据您选择的特定记录器而有所不同
请注意,使用此方法也不需要条件编译指令,因为大多数记录器都有减少/消除将输出写入日志的方法。这使得代码更容易阅读,因为条件编译行增加了很多混乱。使用 plog,可以通过将 init 语句更改为以下内容来暂时禁用日志记录:
plog::init(plog::none , "Logfile.txt"); // plog::none eliminates writing of most messages, essentially turning logging off
使用集成调试器:Stepping(步进)
当您运行您的程序时,执行从 main 函数的顶部开始,然后逐个语句按顺序执行,直到程序结束。在你的程序运行的任何时间点,程序都在跟踪很多事情:你正在使用的变量的值,调用了哪些函数(这样当这些函数返回时,程序就会知道在哪里返回),以及程序中的当前执行点(因此它知道接下来要执行哪个语句)。所有这些跟踪信息都称为您的程序状态(或简称为状态)
Stepping 是一组相关调试器功能的名称,这些功能让我们逐条语句地执行(单步执行)我们的代码
箭头标记表示接下来将执行所指向的行
Step into
步入 命令执行程序正常执行路径中的下一条语句,然后暂停程序的执行,以便我们可以使用调试器检查程序的状态。如果正在执行的语句包含一个函数调用,step into 会使程序跳转到被调用函数的顶部,并在那里暂停
Step over
同步入命令一样,步过命令执行程序正常执行路径中的下一条语句。然而,step into 将输入函数调用并逐行执行它们,step over 将不间断地执行整个函数,并在函数执行后将控制权返回给您
step over 命令提供了一种方便的方法来跳过函数,当您确定它们已经工作或现在对调试它们不感兴趣时
Step out
与其他两个步进命令不同,步出 命令不只是执行下一行代码。相反,它执行当前正在执行的函数中的所有剩余代码,然后在函数返回时将控制权返回给您
当你不小心进入了一个你不想调试的函数时,这个命令最有用
使用集成调试器:Running and breakpoints(运行和断点)
Run to cursor
第一个有用的命令通常称为运行到光标。此运行到光标命令执行程序,直到执行到达光标选择的语句。然后它将控制权返回给您,以便您可以从那时开始进行调试
Breakpoints
断点 是一个特殊的标记,它告诉调试器在调试模式下运行时在断点处停止执行程序
使用集成调试器:调用堆栈
调用堆栈是为到达当前执行点而调用的所有活动函数的列表。调用堆栈包括每个调用的函数的条目,以及函数返回时将返回到哪一行代码。每当调用一个新函数时,该函数就会被添加到调用堆栈的顶部。当前函数返回给调用者时,它会从调用栈的顶部移除,控制权会返回到它下面的函数
调用堆栈窗口是一个显示当前调用堆栈的调试器窗口
函数名称后的行号显示了每个函数中要执行的下一行
由于调用堆栈的顶部条目代表当前正在执行的函数,因此此处的行号显示了执行恢复时将执行的下一行。调用堆栈中的其余条目表示将在某个时间点返回的函数,因此这些条目的行号表示函数返回后将执行的下一条语句
在问题成为问题之前发现问题
重构你的代码
当您向程序添加新功能(“行为更改”)时,您会发现某些功能的长度会增加。随着函数越来越长,它们变得越来越复杂,也越来越难以理解
解决此问题的一种方法是将单个长函数分解为多个较短的函数。这种在不改变代码行为的情况下对代码进行结构更改的过程(通常是为了使您的程序更有组织性、模块化或性能)称为重构
一个函数占据一个垂直屏幕的代码通常被认为太长了——如果你必须滚动才能阅读整个函数,函数的可理解性会显着下降。但越短越好 – 少于十行的功能是好的。少于五行的函数就更好了
更改代码时,进行行为更改或结构更改,然后重新测试正确性。同时进行行为和结构更改往往会导致更多错误以及更难发现的错误
约束
基于约束的技术涉及添加一些额外的代码(如果需要,可以在非调试构建中编译出来)以检查是否违反了某些假设或期望集
例如,如果我们正在编写一个函数来计算一个数字的阶乘,它需要一个非负参数,该函数可以检查以确保调用者在继续之前传递了一个非负数。如果调用者传入一个负数,那么该函数可能会立即出错,而不是产生一些不确定的结果,从而有助于确保立即发现问题
一种常见的方法是通过 assert 和 static_assert
基本数据类型
数据类型大小
数据类型的大小取决于编译器和计算机体系结构!
C++ 仅保证每个基本数据类型都具有最小大小
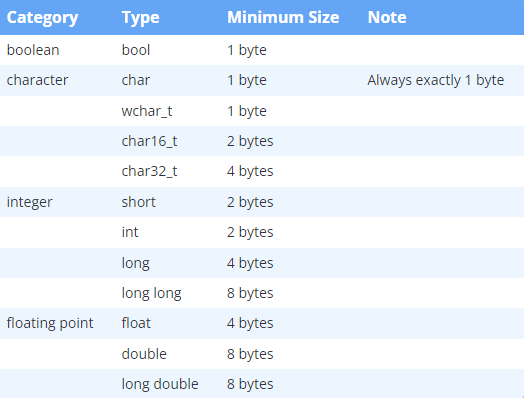
为了获得最大的兼容性,您不应假设变量大于指定的最小大小
#include <iostream>
int main()
{
std::cout << "bool:\t\t" << sizeof(bool) << " bytes\n";
std::cout << "char:\t\t" << sizeof(char) << " bytes\n";
std::cout << "wchar_t:\t" << sizeof(wchar_t) << " bytes\n";
std::cout << "char16_t:\t" << sizeof(char16_t) << " bytes\n";
std::cout << "char32_t:\t" << sizeof(char32_t) << " bytes\n";
std::cout << "short:\t\t" << sizeof(short) << " bytes\n";
std::cout << "int:\t\t" << sizeof(int) << " bytes\n";
std::cout << "long:\t\t" << sizeof(long) << " bytes\n";
std::cout << "long long:\t" << sizeof(long long) << " bytes\n";
std::cout << "float:\t\t" << sizeof(float) << " bytes\n";
std::cout << "double:\t\t" << sizeof(double) << " bytes\n";
std::cout << "long double:\t" << sizeof(long double) << " bytes\n";
return 0;
}
下面是我的 x64 机器的输出,使用 Clion:
bool: 1 bytes
char: 1 bytes
wchar_t: 2 bytes
char16_t: 2 bytes
char32_t: 4 bytes
short: 2 bytes
int: 4 bytes
long: 4 bytes
long long: 8 bytes
float: 4 bytes
double: 8 bytes
long double: 16 bytes
如果您使用不同类型的机器或不同的编译器,您的结果可能会有所不同。请注意,您不能对 void 类型使用 sizeof 运算符,因为它没有大小(这样做会导致编译错误)
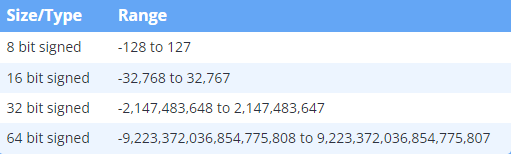
无符号整数和有符号整数
有符号整数范围:
无符号整数范围:
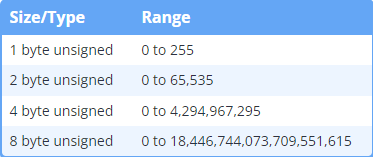
如果无符号整数超出范围,则将其除以大于该类型的最大数,只保留余数
在 C++ 的数学运算中(例如算术或比较),如果使用一个有符号整数和一个无符号整数,则有符号整数将转换为无符号整数。并且无符号整数不能存储负数,这会导致数据丢失
在保存整数(甚至应该是非负的整数)和数学运算时,有符号数优于无符号数。避免混合有符号和无符号数字
在 C++ 中仍然有一些情况必须使用无符号数:
首先,在处理位操作时首选无符号数。当需要明确定义的环绕行为时,它们也很有用(在某些算法中很有用,例如加密和随机数生成)
其次,无符号数的使用在某些情况下仍然是不可避免的,主要是那些与数组索引有关的情况。。在这些情况下,无符号值可以转换为有符号值
固定宽度整数和 size_t
Fixed-width 整数
为什么整数变量的大小不固定?
这可以追溯到 C,当时计算机速度很慢,性能是最受关注的问题。 C 选择有意保留整数的大小,以便编译器实现者可以选择在目标计算机体系结构上表现最佳的 int 大小
C99 定义了一组固定宽度的整数(在 stdint.h 头文件中),保证在任何体系结构上都具有相同的大小
C++ 正式采用这些固定宽度整数作为 C++11 的一部分。可以通过包含 <cstdint> 头文件来访问它们,它们在 std 命名空间内定义
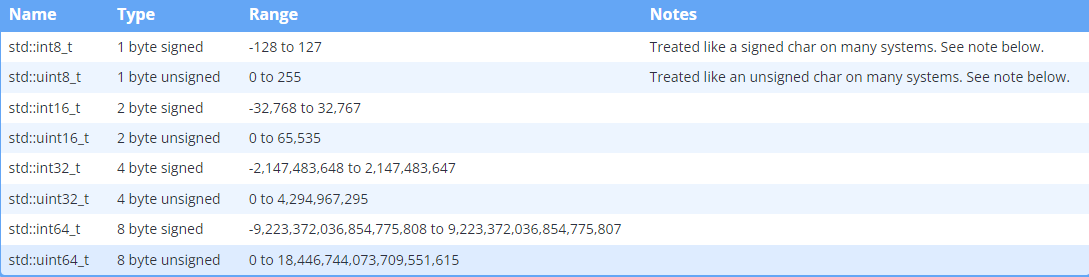
Fast and least 整数
The fast 类型(std::int_fast#_t 和 std::uint_fast#_t)提供最快的有符号/无符号整数类型,宽度至少为 # 位(其中 # = 8、16、32 或 64)。例如,std::int_fast32_t 将为您提供最快的至少 32 位的有符号整数类型
The least 类型(std::int_least#_t 和 std::uint_least#_t)提供宽度至少为 # 位(其中 # = 8、16、32 或 64)的最小有符号/无符号整数类型。例如,std::uint_least32_t 将为您提供至少 32 位的最小无符号整数类型
示例:
#include <cstdint> // for fixed-width integers
#include <iostream>
int main()
{
std::cout << "least 8: " << sizeof(std::int_least8_t) * 8 << " bits\n";
std::cout << "least 16: " << sizeof(std::int_least16_t) * 8 << " bits\n";
std::cout << "least 32: " << sizeof(std::int_least32_t) * 8 << " bits\n";
std::cout << '\n';
std::cout << "fast 8: " << sizeof(std::int_fast8_t) * 8 << " bits\n";
std::cout << "fast 16: " << sizeof(std::int_fast16_t) * 8 << " bits\n";
std::cout << "fast 32: " << sizeof(std::int_fast32_t) * 8 << " bits\n";
return 0;
}
Result:
least 8: 8 bits
least 16: 16 bits
least 32: 32 bits
fast 8: 8 bits
fast 16: 16 bits
fast 32: 32 bits
然而,这些快速且最小的整数有其自身的缺点:首先,真正使用它们的程序员并不多,不熟悉会导致错误。其次,快速类型会导致与我们在 4 字节整数中看到的相同类型的内存浪费。最严重的是,由于快速/最小整数的大小可能会有所不同,因此您的程序可能会在解析为不同大小的架构上表现出不同的行为
std::int8_t 和 std::uint8_t 可能表现得像字符而不是整数
由于 C++ 规范中的疏忽,大多数编译器分别将 std::int8_t 和 std::uint8_t(以及相应的快速和最小固定宽度类型)定义为 signed char 和 unsigned char 类型,并将其视为相同的类型。这意味着这些 8 位类型的行为可能(或可能不)与其他固定宽度类型不同,这可能会导致错误。此行为是系统相关的,因此在一种体系结构上正确运行的程序可能无法编译或在另一种体系结构上正确运行
为了保持一致性,最好完全避免使用 std::int8_t 和 std::uint8_t(以及相关的快速和最少类型)(改用 std::int16_t 或 std::uint16_t)
8 位固定宽度整数类型通常被视为字符而不是整数值(这可能因系统而异)。大多数情况下首选 16 位固定整数类型
Best practice
我们的立场是正确比快速更好,在编译时失败比运行时更好——因此,我们建议避免使用快速/最少的类型,而使用固定宽度的类型。如果您后来发现需要支持无法编译固定宽度类型的平台,那么您可以在此时决定如何迁移您的程序(并彻底测试)
- 当整数的大小无关紧要时,首选 int(例如,数字将始终适合 2 字节有符号整数的范围)。例如,如果您要求用户输入他们的年龄,或者从 1 数到 10,则 int 是 16 位还是 32 位都没有关系(数字将适合任何一种方式)。这将涵盖您可能遇到的绝大多数情况
- 存储需要保证范围的数量时,首选
std::int#_t - 在进行位操作或需要明确定义的环绕行为时,首选
std::uint#_t - 尽可能避免以下情况:
- 存储数量的无符号类型
- 8 位固定宽度整数类型
- Fast and least 整数类型
- 任何特定于编译器的固定宽度整数——例如,Visual Studio 定义了
__int8、__int16……
size_t
sizeof(以及许多返回大小或长度值的函数)返回一个 std::size_t 类型的值。 std::size_t 被定义为无符号整数类型,通常用于表示对象的大小或长度
有趣的是,我们可以使用 sizeof 运算符(返回 std::size_t 类型的值)来询问 std::size_t 本身的大小:
#include <cstddef> // std::size_t
#include <iostream>
int main()
{
std::cout << sizeof(std::size_t) << '\n';
return 0;
}
就像整数的大小会因系统而异一样,std::size_t 的大小也会有所不同。 std::size_t 保证为无符号且至少为 16 位,但在大多数系统上将等同于应用程序的地址宽度。也就是说,对于 32 位应用程序,std::size_t 通常是 32 位无符号整数,而对于 64 位应用程序,size_t 通常是 64 位无符号整数。 size_t 被定义为足够大以容纳系统上可创建的最大对象的大小(以字节为单位)。例如,如果 std::size_t 为 4 字节宽,则系统上可创建的最大对象不能大于 4,294,967,295 字节,因为 4,294,967,295 是 4 字节无符号整数可以存储的最大数字。这只是对象大小的上限,实际大小限制可能会更低,具体取决于您使用的编译器
根据定义,任何大小(以字节为单位)大于 size_t 可以容纳的最大整数值的对象都被视为格式错误(并将导致编译错误),因为 sizeof 运算符将无法在不环绕的情况下返回大小
浮点数(IEEE 754)
浮点范围和浮点精度
使用浮点文字时,始终至少包含一位小数(即使小数为 0)。这有助于编译器理解该数字是浮点数而不是整数
int x{5}; // 5 means integer
double y{5.0}; // 5.0 is a floating point literal (no suffix means double type by default)
float z{5.0f}; // 5.0 is a floating point literal, f suffix means float type
始终确保字面量的类型与分配给它们或用于初始化的变量的类型相匹配。否则会导致不必要的转换,可能会导致精度损失
确保在应该使用浮点文字的地方不使用整数文字。这包括初始化浮点对象或为浮点对象赋值、进行浮点运算以及调用需要浮点值的函数
输出浮点数时,std::cout 的默认精度为 6——也就是说,它假定所有浮点变量仅对 6 位有效(浮点数的最小精度),因此它将截断之后的任何内容
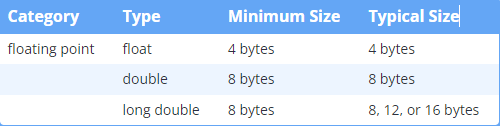
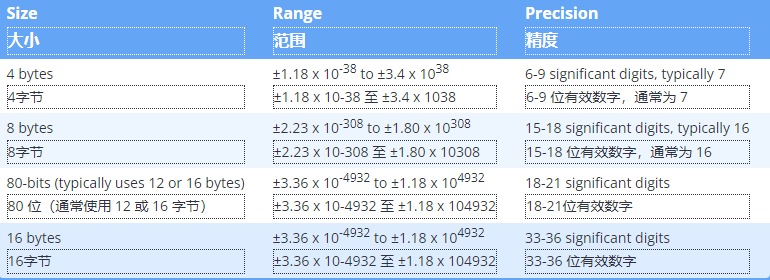
浮点变量的精度位数取决于大小(浮点数的精度低于双精度数)和存储的特定值(某些值的精度高于其他值)。浮点值的精度在 6 到 9 位之间,大多数浮点值至少有 7 位有效数字。双精度值的精度在 15 到 18 位之间,大多数双精度值至少有 16 位有效数字。 Long double 的最小精度为 15、18 或 33 位有效数字,具体取决于它占用的字节数
舍入误差
我们可以使用名为 std::setprecision() 的输出操纵器函数覆盖 std::cout 显示的默认精度。输出操纵器改变数据的输出方式,并在 iomanip 标头中定义
#include <iostream>
#include <iomanip> // for output manipulator std::setprecision()
int main()
{
std::cout << std::setprecision(16); // show 16 digits of precision
std::cout << 3.33333333333333333333333333333333333333f <<'\n'; // f suffix means float
std::cout << 3.33333333333333333333333333333333333333 << '\n'; // no suffix means double
return 0;
}
在使用需要比变量所能容纳的精度更高的浮点数时,必须小心
除非空间非常宝贵,否则最好使用 double over float,因为 float 缺乏精度通常会导致不准确
值 123456789.0 具有 10 位有效数字,但浮点值通常具有 7 位精度(而 123456792 的结果仅精确到 7 位有效数字)。我们失去了一些精度!当由于无法精确存储数字而导致精度丢失时,这称为舍入误差
数学运算(例如加法和乘法)往往会使舍入误差增大。所以即使0.1在第17位有效位有舍入误差,但是当我们加上0.1十次时,舍入误差已经爬到第16位有效位了。继续操作会导致此错误变得越来越严重
NaN 和 Inf
有两种特殊类别的浮点数。第一个是 Inf,代表无穷大。 Inf 可以是正数或负数。第二个是 NaN,代表“不是数字”。有几种不同类型的 NaN(我们不会在这里讨论)。 NaN 和 Inf 仅在编译器对浮点数使用特定格式 (IEEE 754) 时可用
Conclusion
总而言之,关于浮点数你应该记住两件事:
浮点数对于存储非常大或非常小的数字很有用,包括带有小数部分的数字
浮点数通常有小的舍入误差,即使数字的有效数字少于精度也是如此。很多时候这些都没有引起注意,因为它们太小了,而且因为输出的数字被截断了。但是,浮点数的比较可能不会给出预期的结果。对这些值执行数学运算将导致舍入误差变大
布尔值
如果您希望 std::cout 打印“true”或“false”而不是 0 或 1,您可以使用 std::boolalpha。这是一个例子:
#include <iostream>
int main()
{
std::cout << true << '\n';
std::cout << false << '\n';
std::cout << std::boolalpha; // print bools as true or false
std::cout << true << '\n';
std::cout << false << '\n';
return 0;
}
您可以使用 std::noboolalpha 将其关闭
您不能使用除 0 1 外的整数初始化布尔值:
#include <iostream>
int main()
{
bool b{ 4 }; // error: narrowing conversions disallowed
std::cout << b;
return 0;
}
但是,在任何可以将整数转换为布尔值的上下文中,整数 0 将转换为 false,而任何其他整数将转换为 true
事实证明,std::cin 只接受布尔变量的两个输入:0 和 1(不是 true 或 false)。任何其他输入都会导致 std::cin 无声地失败。在这种情况下,因为我们输入了 true,所以 std::cin 默默地失败了。失败的输入也会将变量清零,因此 b 也被赋值 false。因此,当 std::cout 打印 b 的值时,它打印 0
要允许 std::cin 接受“false”和“true”作为输入,必须启用 std::boolalpha 选项:
#include <iostream>
int main()
{
bool b{};
std::cout << "Enter a boolean value: ";
// Allow the user to enter 'true' or 'false' for boolean values
// This is case-sensitive, so True or TRUE will not work
std::cin >> std::boolalpha;
std::cin >> b;
std::cout << "You entered: " << b << '\n';
return 0;
}
但是,当启用 std::boolalpha 时,“0”和“1”将不再被视为布尔值
Chars
char 数据类型旨在保存单个字符。字符可以是单个字母、数字、符号或空格
char 数据类型是整数类型,这意味着基础值存储为整数。类似于布尔值 0 被解释为 false 而非零被解释为 true 的方式,char 变量存储的整数被解释为 ASCII 字符
Char 由 C++ 定义为大小始终为 1 个字节。默认情况下,char 可以是有符号的或无符号的(尽管它通常是有符号的)。如果您使用 chars 来保存 ASCII 字符,则不需要指定符号(因为有符号和无符号字符都可以保存 0 到 127 之间的值)
如果您使用 char 来保存小整数(除非您明确优化空间,否则您不应该这样做),您应该始终指定它是有符号的还是无符号的。 signed char 可以保存 -128 到 127 之间的数字。unsigned char 可以保存 0 到 255 之间的数字
将单个字符放在单引号中( e.g. 't' or '\n', not "t" or "\n")这有助于编译器更有效地进行优化
出于向后兼容性的原因,许多 C++ 编译器支持多字符文字,即包含多个字符(例如“56”)的字符文字。如果支持,它们具有实现定义的值(意味着它因编译器而异)。因为它们不是 C++ 标准的一部分,而且它们的值也没有严格定义,所以应该避免使用多字符文字
ASCII 之外最著名的映射是 Unicode 标准,它将超过 144,000 个整数映射到许多不同语言的字符。由于 Unicode 包含如此多的代码点,因此单个 Unicode 代码点需要 32 位来表示一个字符(称为 UTF-32)。但是,Unicode 字符也可以使用多个 16 位或 8 位字符(分别称为 UTF-16 和 UTF-8)进行编码
char16_t 和 char32_t 添加到 C++11 以提供对 16 位和 32 位 Unicode 字符的明确支持。 C++20 中添加了 char8_t
您不需要使用 char8_t、char16_t 或 char32_t,除非您计划让您的程序与 Unicode 兼容
同时,在处理字符(和字符串)时,您应该只使用 ASCII 字符。使用来自其他字符集的字符可能会导致您的字符显示不正确
通过 static_cast 运算符进行显式类型转换
static_cast<new_type>(expression)
static_cast 将表达式中的值作为输入,并返回转换为 new_type 指定类型(例如 int、bool、char、double)的值
#include <iostream>
void print(int x)
{
std::cout << x;
}
int main()
{
print( static_cast<int>(5.5) ); // explicitly convert double value 5.5 to an int
return 0;
}
常量和符号常量
const variables
Const 变量必须在定义它们时进行初始化,然后不能通过赋值更改该值
Const 变量可以从其他变量(包括非常量变量)初始化
命名时以 “k” 开头, 大小写混合,例如:
const int kDaysInAWeek = 7;
符号常量
符号常量指的是被赋予常量值的名称。const variables 是一种符号常量,因为变量有一个名称(它的标识符)和一个常量值
#include <iostream>
#define MAX_STUDENTS_PER_CLASS 30
int main()
{
std::cout << "The class has " << MAX_STUDENTS_PER_CLASS << " students.\n";
return 0;
}
编译此程序时,预处理器会将 MAX_STUDENTS_PER_CLASS 替换为字面值 30,然后编译器会将其编译为您的可执行文件
因为类对象宏有一个名字,并且替换文本是一个常量值,所以带有替换文本的类对象宏也是符号常量
对于符号常量,更喜欢常量变量而不是类对象宏
首先,因为宏是由预处理器解析的,所有出现的宏都在编译之前被定义的值替换。如果您正在调试代码,您将看不到实际值(例如 30)——您只会看到符号常量的名称(例如 MAX_STUDENTS_PER_CLASS)。因为这些#defined 值不是变量,所以您无法在调试器中添加监视来查看它们的值。如果您想知道 MAX_STUDENTS_PER_CLASS 解析为什么值,您必须找到 MAX_STUDENTS_PER_CLASS 的定义(可能在不同的文件中)。这会使您的程序更难调试
其次,宏可能与普通代码有命名冲突
第三,宏不遵循正常的作用域规则,这意味着在极少数情况下,在程序的一部分中定义的宏可能会与在程序的另一部分中编写的代码发生冲突,而它不应该与之交互
编译时常量、常量表达式和 constexpr
Constant expressions
常量表达式是可以在编译时由编译器求值的表达式。要成为常量表达式,表达式中的所有值必须在编译时已知(并且所有调用的运算符和函数必须支持编译时求值)
在编译时对常量表达式求值会使我们的编译时间变长(因为编译器必须做更多的工作),但这样的表达式只需要求值一次(而不是每次程序运行时)。生成的可执行文件速度更快,使用的内存更少
Compile-time constants
编译时常量是其值在编译时已知的常量。文字(例如“1”、“2.3”和“Hello, world!”)是一种编译时常量
Const 变量可能是也可能不是编译时常量
Compile-time const
如果 const 变量的初始值设定项是常量表达式,则它是编译时常量
#include <iostream>
int main()
{
const int x { 3 }; // x is a compile-time const
const int y { 4 }; // y is a compile-time const
const int z { x + y }; // x + y is a compile-time expression
std::cout << z << '\n';
return 0;
}
因为 x 和 y 的初始化值是常量表达式,所以 x 和 y 是编译时常量。这意味着 x + y 也是常量表达式。所以当编译器编译这个程序时,它可以计算 x + y 的值,并将常量表达式替换为结果文字 7
Runtime const
任何使用非常量表达式初始化的 const 变量都是运行时常量。运行时常量是其初始化值直到运行时才知道的常量
#include <iostream>
int getNumber()
{
std::cout << "Enter a number: ";
int y{};
std::cin >> y;
return y;
}
int main()
{
const int x{ 3 }; // x is a compile time constant
const int y{ getNumber() }; // y is a runtime constant
const int z{ x + y }; // x + y is a runtime expression
std::cout << z << '\n'; // this is also a runtime expression
return 0;
}
即使 y 是常量,初始化值(getNumber() 的返回值)直到运行时才知道。因此,y 是运行时常量,而不是编译时常量。因此,表达式 x + y 是一个运行时表达式
constexpr 关键字
当你声明一个 const 变量时,编译器会隐式地跟踪它是运行时常量还是编译时常量。在大多数情况下,除了优化目的之外,这无关紧要,但有一些奇怪的情况,C++ 需要编译时常量而不是运行时常量
因为编译时常量通常允许更好的优化(并且几乎没有缺点),所以我们通常希望尽可能使用编译时常量
我们可以寻求编译器的帮助,以确保我们得到一个我们期望的编译时常量。为此,我们在变量声明中使用 constexpr 关键字而不是 const。 constexpr(“常量表达式”的缩写)变量只能是编译时常量。如果 constexpr 变量的初始化值不是常量表达式,编译器会出错
#include <iostream>
int five()
{
return 5;
}
int main()
{
constexpr double gravity { 9.8 }; // ok: 9.8 is a constant expression
constexpr int sum { 4 + 5 }; // ok: 4 + 5 is a constant expression
constexpr int something { sum }; // ok: sum is a constant expression
std::cout << "Enter your age: ";
int age{};
std::cin >> age;
constexpr int myAge { age }; // compile error: age is not a constant expression
constexpr int f { five() }; // compile error: return value of five() is not a constant expression
return 0;
}
任何在初始化后不应修改且其初始值设定项在编译时已知的变量都应声明为 constexpr
任何在初始化后不应修改且其初始值设定项在编译时未知的变量都应声明为 const
Literals
文字是直接插入代码中的未命名值。例如:
return 5; // 5 is an integer literal
bool myNameIsAlex { true }; // true is a boolean literal
std::cout << 3.4; // 3.4 is a double literal
如对象有类型一样,所有文字都有类型。文字的类型是从文字的值推导出来的
十进制、二进制、十六进制和八进制
二进制文字和数字分隔符
在 C++14 之前,不支持二进制文字。然而,十六进制文字为我们提供了一个有用的解决方法(您可能仍会在现有代码库中看到):
#include <iostream>
int main()
{
int bin{}; // assume 16-bit ints
bin = 0x0001; // assign binary 0000 0000 0000 0001 to the variable
bin = 0x0002; // assign binary 0000 0000 0000 0010 to the variable
bin = 0x0004; // assign binary 0000 0000 0000 0100 to the variable
bin = 0x0008; // assign binary 0000 0000 0000 1000 to the variable
bin = 0x0010; // assign binary 0000 0000 0001 0000 to the variable
bin = 0x0020; // assign binary 0000 0000 0010 0000 to the variable
bin = 0x0040; // assign binary 0000 0000 0100 0000 to the variable
bin = 0x0080; // assign binary 0000 0000 1000 0000 to the variable
bin = 0x00FF; // assign binary 0000 0000 1111 1111 to the variable
bin = 0x00B3; // assign binary 0000 0000 1011 0011 to the variable
bin = 0xF770; // assign binary 1111 0111 0111 0000 to the variable
return 0;
}
在 C++14 中,我们可以通过使用 0b 前缀来使用二进制文字:
#include <iostream>
int main()
{
int bin{}; // assume 16-bit ints
bin = 0b1; // assign binary 0000 0000 0000 0001 to the variable
bin = 0b11; // assign binary 0000 0000 0000 0011 to the variable
bin = 0b1010; // assign binary 0000 0000 0000 1010 to the variable
bin = 0b11110000; // assign binary 0000 0000 1111 0000 to the variable
return 0;
}
由于长文本可能难以阅读,C++14 还添加了使用引号 (‘) 作为数字分隔符的功能(分隔符不能出现在值的第一位数字之前)(数字分隔符纯粹是视觉上的,不会以任何方式影响字面值)
#include <iostream>
int main()
{
int bin { 0b1011'0010 }; // assign binary 1011 0010 to the variable
long value { 2'132'673'462 }; // much easier to read than 2132673462
return 0;
}
以十进制、八进制或十六进制输出值
默认情况下,C++ 以十进制形式输出值。但是,您可以通过使用 std::dec、std::oct 和 std::hex I/O 操纵器更改输出格式:
#include <iostream>
int main()
{
int x { 12 };
std::cout << x << '\n'; // decimal (by default)
std::cout << std::hex << x << '\n'; // hexadecimal
std::cout << x << '\n'; // now hexadecimal
std::cout << std::oct << x << '\n'; // octal
std::cout << std::dec << x << '\n'; // return to decimal
std::cout << x << '\n'; // decimal
return 0;
}
以二进制输出值
以二进制形式输出值有点困难,因为 std::cout 没有内置此功能。幸运的是,C++ 标准库包含一个名为 std::bitset 的类型,它将为我们完成此操作(在 <bitset> 标头中)。要使用 std::bitset,我们可以定义一个 std::bitset 变量并告诉 std::bitset 我们要存储多少位。位数必须是编译时常量。 std::bitset 可以用无符号整数值(任何格式,包括十进制、八进制、十六进制或二进制)初始化
#include <bitset> // for std::bitset
#include <iostream>
int main()
{
// std::bitset<8> means we want to store 8 bits
std::bitset<8> bin1{ 0b1100'0101 }; // binary literal for binary 1100 0101
std::bitset<8> bin2{ 0xC5 }; // hexadecimal literal for binary 1100 0101
std::cout << bin1 << '\n' << bin2 << '\n';
std::cout << std::bitset<4>{ 0b1010 } << '\n'; // create a temporary std::bitset and print it
return 0;
}
std::string
使用 std::getline() 输入文本
事实证明,当使用 operator» 从 std::cin 中提取字符串时,operator» 只返回它遇到的第一个空格之前的字符。任何其他字符都留在 std::cin 中,等待下一次提取
要将整行输入读入字符串,最好改用 std::getline() 函数。 std::getline() 需要两个参数:第一个是 std::cin,第二个是您的字符串变量
#include <string> // For std::string and std::getline
#include <iostream>
int main()
{
std::cout << "Enter your full name: ";
std::string name{};
std::getline(std::cin >> std::ws, name); // read a full line of text into name
std::cout << "Enter your age: ";
std::string age{};
std::getline(std::cin >> std::ws, age); // read a full line of text into age
std::cout << "Your name is " << name << " and your age is " << age << '\n';
return 0;
}
std::ws 输入操纵器告诉 std::cin 在提取之前忽略任何前导空格。前导空白是出现在字符串开头的任何空白字符(空格、制表符、换行符)
如果使用 std::getline() 读取字符串,请使用 std::cin >> std::ws 输入操纵器忽略前导空格
将提取运算符 (») 与 std::cin 一起使用会忽略前导空格
std::getline() 不会忽略前导空格,除非您使用输入操纵器 std::ws
字符串长度
如果我们想知道 std::string 中有多少个字符,我们可以向 std::string 对象询问它的长度。注意 std::string::length() 返回一个无符号整数值(很可能是 size_t 类型)。如果你想将长度分配给一个 int 变量,你应该对其进行 static_cast 以避免编译器关于有符号/无符号转换的警告:
int length { static_cast<int>(name.length()) };
std::string 的初始化和复制开销很大
每当初始化 std::string 时,都会生成用于初始化它的字符串的副本。每当 std::string 按值传递给 std::string 参数时,都会生成另一个副本。不要按值传递 std::string,因为生成 std::string 的副本开销很大。更喜欢 std::string_view 参数
Literals for std::string & std::string_view
双引号字符串文字(比如“Hello, world!”)默认是 C 风格的字符串
我们可以通过在双引号字符串文字后使用 s 后缀来创建类型为 std::string 的字符串文字
#include <iostream>
#include <string> // for std::string
#include <string_view> // for std::string_view
int main()
{
using namespace std::literals; // easiest way to access the s and sv suffixes
std::cout << "foo\n"; // no suffix is a C-style string literal
std::cout << "goo\n"s; // s suffix is a std::string literal
std::cout << "moo\n"sv; // sv suffix is a std::string_view literal
return 0;
}
“s”后缀位于命名空间 std::literals::string_literals 中。“sv”后缀位于命名空间 std::literals::string_view_literals 中。访问文字后缀的最简单方法是通过使用指令使用命名空间 std::literals。这是可以使用整个命名空间的例外情况之一,因为其中定义的后缀不太可能与您的任何代码冲突
你可能不需要经常使用 std::string 文字(因为用 C 风格的字符串文字初始化 std::string 对象很好),但我们会在以后的课程中看到一些使用 std 的情况::string literals 而不是 C 风格的 string literals 使事情变得更容易
Constexpr 字符串
如果您尝试定义一个 constexpr std::string,您的编译器可能会产生一个错误
#include <iostream>
#include <string>
using namespace std::literals;
int main()
{
constexpr std::string name{ "Alex"s }; // compile error
std::cout << "My name is: " << name;
return 0;
}
发生这种情况是因为 constexpr std::string 在 C++17 或更早版本中不受支持,并且在 C++20 中仅提供最低限度的支持。如果您需要 constexpr 字符串,请改用 std::string_view
std::string_view
std::string_view C++17
为了解决 std::string 初始化(或复制)成本高昂的问题,C++17 引入了 std::string_view(位于 <string_view> 标头中)。 std::string_view 提供对现有字符串(C 风格字符串文字、std::string 或 char 数组)的只读访问,而无需制作副本
#include <iostream>
#include <string_view>
void printSV(std::string_view str) // now a std::string_view
{
std::cout << str << '\n';
}
int main()
{
std::string_view s{ "Hello, world!" }; // now a std::string_view
printSV(s);
return 0;
}
当我们用 C 风格的字符串文字“Hello, world!”初始化 std::string_view s 时,s 提供对“Hello, world!”的只读访问。无需复制字符串。当我们将 s 传递给 printSV() 时,参数 str 从 s 初始化。这使我们能够通过 str 访问“Hello, world!”,不用再次复制字符串
当您需要只读字符串时,尤其是对于函数参数,优先使用 std::string_view 而不是 std::string
constexpr std::string_view
std::string_view 完全支持 constexpr:
#include <iostream>
#include <string_view>
int main()
{
constexpr std::string_view s{ "Hello, world!" };
std::cout << s << '\n'; // s will be replaced with "Hello, world!" at compile-time
return 0;
}
std::string & std::string_view
可以使用 std::string 初始值设定项创建 std::string_view,并且 std::string 将隐式转换为 std::string_view:
#include <iostream>
#include <string>
#include <string_view>
void printSV(std::string_view str)
{
std::cout << str << '\n';
}
int main()
{
std::string s{ "Hello, world" };
std::string_view sv{ s }; // Initialize a std::string_view from a std::string
std::cout << sv << '\n';
printSV(s); // implicitly convert a std::string to std::string_view
return 0;
}
因为 std::string 复制了它的初始化器(这开销很大),C++ 不允许将 std::string_view 隐式转换为 std::string。但是,我们可以使用 std::string_view 初始值设定项显式创建 std::string,或者我们可以使用 static_cast 将现有的 std::string_view 转换为 std::string
#include <iostream>
#include <string>
#include <string_view>
void printString(std::string str)
{
std::cout << str << '\n';
}
int main()
{
std::string_view sv{ "balloon" };
std::string str{ sv }; // okay, we can create std::string using std::string_view initializer
// printString(sv); // compile error: won't implicitly convert std::string_view to a std::string
printString(static_cast<std::string>(sv)); // okay, we can explicitly cast a std::string_view to a std::string
return 0;
}
Operators(操作符)
, & ? : 运算符
C++ 没有定义函数参数或运算符操作数的计算顺序
不要在给定语句中多次使用具有副作用的变量。如果这样做,结果可能是未定义的
逗号在所有运算符中的优先级最低,甚至低于赋值
请注意, ? : 运算符的优先级非常低。如果除了将结果分配给变量之外做任何事情,整个 ? : 运算符也需要用括号括起来
std::cout << ((x > y) ? x : y) << '\n';
如果在上述情况下我们不将整个条件运算符括起来会发生什么。因为 « 运算符的优先级高于 ?: 运算符,所以语句:
std::cout << (x > y) ? x : y << '\n';
将评估为:
(std::cout << (x > y)) ? x : y << '\n';
比较浮点数大小
进行浮点相等的最常见方法涉及使用一个函数来查看两个数字是否几乎相同。如果它们“足够接近”,那么我们称它们相等。用于表示“足够接近”的值传统上称为 epsilon。 Epsilon 通常被定义为一个小的正数(例如 0.00000001,有时写作 1e-8)
#include <cmath> // for std::abs()
// epsilon is an absolute value
bool approximatelyEqualAbs(double a, double b, double absEpsilon)
{
// if the distance between a and b is less than absEpsilon, then a and b are "close enough"
return std::abs(a - b) <= absEpsilon;
}
虽然这个功能可以工作,但不是很好。 0.00001 的 epsilon 适用于 1.0 左右的输入,对于 0.0000001 左右的输入太大,对于 10,000 这样的输入太小
著名计算机科学家唐纳德·高德纳 (Donald Knuth) 在他的著作“计算机编程的艺术,第二卷:半数值算法 (Addison-Wesley, 1969)”一书中提出了以下方法:
#include <algorithm> // std::max
#include <cmath> // std::abs
// return true if the difference between a and b is within epsilon percent of the larger of a and b
bool approximatelyEqualRel(double a, double b, double relEpsilon)
{
return (std::abs(a - b) <= (std::max(std::abs(a), std::abs(b)) * relEpsilon));
}
在这种情况下,epsilon 不是绝对数字,而是相对于 a 或 b 的大小。在 <= 运算符的左侧,std::abs(a - b) 告诉我们 a 和 b 之间的距离为正数。在 <= 运算符的右侧,我们需要计算我们愿意接受的“足够接近”的最大值。为此,该算法选择 a 和 b 中较大的一个(作为数字总体大小的粗略指标),然后将其乘以 relEpsilon。在此函数中,relEpsilon 表示百分比。例如,如果我们想说“足够接近”意味着 a 和 b 在 a 和 b 中较大者的 1% 以内,我们传入 0.01 (1% = 1/100 = 0.01) 的 relEpsilon。 relEpsilon 的值可以根据情况调整为最合适的值(例如,0.002 的 epsilon 表示在 0.2% 以内)
要执行不等式 (!=) 而不是相等,只需调用此函数并使用逻辑 NOT 运算符 (!) 翻转结果:
if (!approximatelyEqualRel(a, b, 0.001))
std::cout << a << " is not equal to " << b << '\n';
虽然 approximatelyEqualRel() 函数适用于大多数情况,但它并不完美,尤其是当数字接近零时:
#include <algorithm>
#include <cmath>
#include <iostream>
// return true if the difference between a and b is within epsilon percent of the larger of a and b
bool approximatelyEqualRel(double a, double b, double relEpsilon)
{
return (std::abs(a - b) <= (std::max(std::abs(a), std::abs(b)) * relEpsilon));
}
int main()
{
// a is really close to 1.0, but has rounding errors, so it's slightly smaller than 1.0
double a{ 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 };
// First, let's compare a (almost 1.0) to 1.0.
std::cout << approximatelyEqualRel(a, 1.0, 1e-8) << '\n';
// Second, let's compare a-1.0 (almost 0.0) to 0.0
std::cout << approximatelyEqualRel(a-1.0, 0.0, 1e-8) << '\n';
}
这会返回:
1
0
避免这种情况的一种方法是同时使用绝对 epsilon(如我们在第一种方法中所做的)和相对 epsilon(如我们在 Knuth 的方法中所做的):
// return true if the difference between a and b is less than absEpsilon, or within relEpsilon percent of the larger of a and b
bool approximatelyEqualAbsRel(double a, double b, double absEpsilon, double relEpsilon)
{
// Check if the numbers are really close -- needed when comparing numbers near zero.
double diff{ std::abs(a - b) };
if (diff <= absEpsilon)
return true;
// Otherwise fall back to Knuth's algorithm
return (diff <= (std::max(std::abs(a), std::abs(b)) * relEpsilon));
}
在这个算法中,我们首先检查 a 和 b 在绝对值上是否接近,这处理了 a 和 b 都接近于零的情况。 absEpsilon 参数应设置为非常小的值(例如 1e-12)。如果失败,则我们使用相对 epsilon 回退到 Knuth 的算法
浮点数的比较是一个困难的话题,并且没有适用于所有情况的“一刀切”算法。但是,absEpsilon 为 1e-12 和 relEpsilon 为 1e-8 的 approximatesEqualAbsRel() 应该足以处理您将遇到的大多数情况
逻辑 XOR 运算符
C++ 不提供逻辑 XOR 运算符。与逻辑或或逻辑与不同,逻辑异或不能进行短路评估。因此,从逻辑 OR 和逻辑 AND 运算符中创建逻辑 XOR 运算符具有挑战性。但是,您可以使用不等运算符 (!=) 轻松模拟逻辑 XOR:
if (a != b) ... // a XOR b, assuming a and b are Booleans
这可以扩展到多个操作数,如下所示:
if (a != b != c != d) ... // a XOR b XOR c XOR d, assuming a, b, c, and d are Booleans
请注意,上述 XOR 模式仅在操作数为布尔值(而非整数)时才有效。如果您需要一种适用于非布尔操作数的逻辑 XOR 形式,您可以将它们静态转换为布尔值:
if (static_cast<bool>(a) != static_cast<bool>(b) != static_cast<bool>(c) != static_cast<bool>(d)) ... // a XOR b XOR c XOR d, for any type that can be converted to bool
位操作
位标志 and 位操作 via std::bitset
要定义一组位标志,我们通常会使用适当大小的无符号整数(8 位、16 位、32 位等……取决于我们有多少标志),或 std::bitset
#include <bitset> // for std::bitset
std::bitset<8> mybitset {}; // 8 bits in size means room for 8 flags
位操作是您应该明确使用无符号整数(或 std::bitset)的少数情况之一
std::bitset 提供了 4 个可用于位操作的关键函数:
- test() 允许我们查询某个位是 0 还是 1
- set() 允许我们打开一个位(如果位已经打开,这将不执行任何操作)
- reset() 允许我们关闭一个位(如果该位已经关闭,这将不执行任何操作)
- flip() 允许我们将位值从 0 翻转为 1,反之亦然
这些函数中的每一个都将我们要操作的位的位置作为它们唯一的参数
#include <bitset>
#include <iostream>
int main()
{
std::bitset<8> bits{ 0b0000'0101 }; // we need 8 bits, start with bit pattern 0000 0101
bits.set(3); // set bit position 3 to 1 (now we have 0000 1101)
bits.flip(4); // flip bit 4 (now we have 0001 1101)
bits.reset(4); // set bit 4 back to 0 (now we have 0000 1101)
std::cout << "All the bits: " << bits << '\n';
std::cout << "Bit 3 has value: " << bits.test(3) << '\n';
std::cout << "Bit 4 has value: " << bits.test(4) << '\n';
return 0;
}
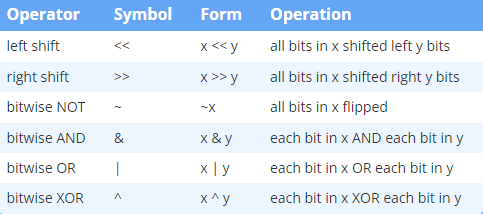
按位运算符
在计算按位 XOR 时,如果一列中有奇数个 1 位,则该列的结果为 1
位掩码
位掩码是一组预定义的位,用于选择哪些特定位将被后续操作修改。位掩码阻止按位运算符接触我们不想修改的位,并允许访问我们确实想要修改的位
最简单的一组位掩码是为每个位位置定义一个位掩码。我们用 0 来屏蔽我们不关心的位,用 1 来表示我们想要修改的位
尽管位掩码可以是文字,但它们通常被定义为符号常量,因此可以为它们指定一个有意义的名称并易于重用
在 C++14 中定义位掩码
因为 C++14 支持二进制文字,所以定义这些位掩码很容易:
#include <cstdint>
constexpr std::uint8_t mask0{ 0b0000'0001 }; // represents bit 0
constexpr std::uint8_t mask1{ 0b0000'0010 }; // represents bit 1
constexpr std::uint8_t mask2{ 0b0000'0100 }; // represents bit 2
constexpr std::uint8_t mask3{ 0b0000'1000 }; // represents bit 3
constexpr std::uint8_t mask4{ 0b0001'0000 }; // represents bit 4
constexpr std::uint8_t mask5{ 0b0010'0000 }; // represents bit 5
constexpr std::uint8_t mask6{ 0b0100'0000 }; // represents bit 6
constexpr std::uint8_t mask7{ 0b1000'0000 }; // represents bit 7
在 C++11 或更早版本中定义位掩码
由于 C++11 不支持二进制文字,我们必须使用其他方法来设置符号常量
第一种方法是使用十六进制文字:
constexpr std::uint8_t mask0{ 0x01 }; // hex for 0000 0001
constexpr std::uint8_t mask1{ 0x02 }; // hex for 0000 0010
constexpr std::uint8_t mask2{ 0x04 }; // hex for 0000 0100
constexpr std::uint8_t mask3{ 0x08 }; // hex for 0000 1000
constexpr std::uint8_t mask4{ 0x10 }; // hex for 0001 0000
constexpr std::uint8_t mask5{ 0x20 }; // hex for 0010 0000
constexpr std::uint8_t mask6{ 0x40 }; // hex for 0100 0000
constexpr std::uint8_t mask7{ 0x80 }; // hex for 1000 0000
另一种更简单的方法是使用左移运算符将一位移动到正确的位置:
constexpr std::uint8_t mask0{ 1 << 0 }; // 0000 0001
constexpr std::uint8_t mask1{ 1 << 1 }; // 0000 0010
constexpr std::uint8_t mask2{ 1 << 2 }; // 0000 0100
constexpr std::uint8_t mask3{ 1 << 3 }; // 0000 1000
constexpr std::uint8_t mask4{ 1 << 4 }; // 0001 0000
constexpr std::uint8_t mask5{ 1 << 5 }; // 0010 0000
constexpr std::uint8_t mask6{ 1 << 6 }; // 0100 0000
constexpr std::uint8_t mask7{ 1 << 7 }; // 1000 0000
Testing a bit
要确定某个位是开还是关,我们使用 & 结合相应位的位掩码:
#include <cstdint>
#include <iostream>
int main()
{
constexpr std::uint8_t mask0{ 0b0000'0001 }; // represents bit 0
constexpr std::uint8_t mask1{ 0b0000'0010 }; // represents bit 1
constexpr std::uint8_t mask2{ 0b0000'0100 }; // represents bit 2
constexpr std::uint8_t mask3{ 0b0000'1000 }; // represents bit 3
constexpr std::uint8_t mask4{ 0b0001'0000 }; // represents bit 4
constexpr std::uint8_t mask5{ 0b0010'0000 }; // represents bit 5
constexpr std::uint8_t mask6{ 0b0100'0000 }; // represents bit 6
constexpr std::uint8_t mask7{ 0b1000'0000 }; // represents bit 7
std::uint8_t flags{ 0b0000'0101 }; // 8 bits in size means room for 8 flags
std::cout << "bit 0 is " << ((flags & mask0) ? "on\n" : "off\n");
std::cout << "bit 1 is " << ((flags & mask1) ? "on\n" : "off\n");
return 0;
}
Setting a bit
要设置(打开)位,我们将按位或等于(运算符 |=)与相应位的位掩码结合使用:
#include <cstdint>
#include <iostream>
int main()
{
constexpr std::uint8_t mask0{ 0b0000'0001 }; // represents bit 0
constexpr std::uint8_t mask1{ 0b0000'0010 }; // represents bit 1
constexpr std::uint8_t mask2{ 0b0000'0100 }; // represents bit 2
constexpr std::uint8_t mask3{ 0b0000'1000 }; // represents bit 3
constexpr std::uint8_t mask4{ 0b0001'0000 }; // represents bit 4
constexpr std::uint8_t mask5{ 0b0010'0000 }; // represents bit 5
constexpr std::uint8_t mask6{ 0b0100'0000 }; // represents bit 6
constexpr std::uint8_t mask7{ 0b1000'0000 }; // represents bit 7
std::uint8_t flags{ 0b0000'0101 }; // 8 bits in size means room for 8 flags
std::cout << "bit 1 is " << ((flags & mask1) ? "on\n" : "off\n");
flags |= mask1; // turn on bit 1
std::cout << "bit 1 is " << ((flags & mask1) ? "on\n" : "off\n");
return 0;
}
我们还可以使用按位或同时打开多个位:
flags |= (mask4 | mask5); // turn bits 4 and 5 on at the same time
Resetting a bit
要清除位(关闭),我们同时使用 &= 和 ~ :
#include <cstdint>
#include <iostream>
int main()
{
constexpr std::uint8_t mask0{ 0b0000'0001 }; // represents bit 0
constexpr std::uint8_t mask1{ 0b0000'0010 }; // represents bit 1
constexpr std::uint8_t mask2{ 0b0000'0100 }; // represents bit 2
constexpr std::uint8_t mask3{ 0b0000'1000 }; // represents bit 3
constexpr std::uint8_t mask4{ 0b0001'0000 }; // represents bit 4
constexpr std::uint8_t mask5{ 0b0010'0000 }; // represents bit 5
constexpr std::uint8_t mask6{ 0b0100'0000 }; // represents bit 6
constexpr std::uint8_t mask7{ 0b1000'0000 }; // represents bit 7
std::uint8_t flags{ 0b0000'0101 }; // 8 bits in size means room for 8 flags
std::cout << "bit 2 is " << ((flags & mask2) ? "on\n" : "off\n");
flags &= ~mask2; // turn off bit 2
std::cout << "bit 2 is " << ((flags & mask2) ? "on\n" : "off\n");
return 0;
}
我们可以同时关闭多个位:
flags &= ~(mask4 | mask5); // turn bits 4 and 5 off at the same time
Flipping a bit
要切换位状态,我们使用 ^=:
#include <cstdint>
#include <iostream>
int main()
{
constexpr std::uint8_t mask0{ 0b0000'0001 }; // represents bit 0
constexpr std::uint8_t mask1{ 0b0000'0010 }; // represents bit 1
constexpr std::uint8_t mask2{ 0b0000'0100 }; // represents bit 2
constexpr std::uint8_t mask3{ 0b0000'1000 }; // represents bit 3
constexpr std::uint8_t mask4{ 0b0001'0000 }; // represents bit 4
constexpr std::uint8_t mask5{ 0b0010'0000 }; // represents bit 5
constexpr std::uint8_t mask6{ 0b0100'0000 }; // represents bit 6
constexpr std::uint8_t mask7{ 0b1000'0000 }; // represents bit 7
std::uint8_t flags{ 0b0000'0101 }; // 8 bits in size means room for 8 flags
std::cout << "bit 2 is " << ((flags & mask2) ? "on\n" : "off\n");
flags ^= mask2; // flip bit 2
std::cout << "bit 2 is " << ((flags & mask2) ? "on\n" : "off\n");
flags ^= mask2; // flip bit 2
std::cout << "bit 2 is " << ((flags & mask2) ? "on\n" : "off\n");
return 0;
}
我们可以同时翻转多个位:
flags ^= (mask4 | mask5); // flip bits 4 and 5 at the same time
位掩码和 std::bitset
std::bitset 支持全套位运算符。因此,尽管使用函数(测试、设置、重置和翻转)修改单个位更容易,但如果需要,您可以使用按位运算符和位掩码
函数只允许您一次修改单个位。按位运算符允许您一次修改多个位
#include <cstdint>
#include <iostream>
#include <bitset>
int main()
{
constexpr std::bitset<8> mask0{ 0b0000'0001 }; // represents bit 0
constexpr std::bitset<8> mask1{ 0b0000'0010 }; // represents bit 1
constexpr std::bitset<8> mask2{ 0b0000'0100 }; // represents bit 2
constexpr std::bitset<8> mask3{ 0b0000'1000 }; // represents bit 3
constexpr std::bitset<8> mask4{ 0b0001'0000 }; // represents bit 4
constexpr std::bitset<8> mask5{ 0b0010'0000 }; // represents bit 5
constexpr std::bitset<8> mask6{ 0b0100'0000 }; // represents bit 6
constexpr std::bitset<8> mask7{ 0b1000'0000 }; // represents bit 7
std::bitset<8> flags{ 0b0000'0101 }; // 8 bits in size means room for 8 flags
std::cout << "bit 1 is " << (flags.test(1) ? "on\n" : "off\n");
std::cout << "bit 2 is " << (flags.test(2) ? "on\n" : "off\n");
flags ^= (mask1 | mask2); // flip bits 1 and 2
std::cout << "bit 1 is " << (flags.test(1) ? "on\n" : "off\n");
std::cout << "bit 2 is " << (flags.test(2) ? "on\n" : "off\n");
flags |= (mask1 | mask2); // turn bits 1 and 2 on
std::cout << "bit 1 is " << (flags.test(1) ? "on\n" : "off\n");
std::cout << "bit 2 is " << (flags.test(2) ? "on\n" : "off\n");
flags &= ~(mask1 | mask2); // turn bits 1 and 2 off
std::cout << "bit 1 is " << (flags.test(1) ? "on\n" : "off\n");
std::cout << "bit 2 is " << (flags.test(2) ? "on\n" : "off\n");
return 0;
}
Summary
- query bit states
if (flags & option4) ... // if option4 is set, do something
- set bits (turn on)
flags |= option4; // turn option 4 on.
flags |= (option4 | option5); // turn options 4 and 5 on.
- clear bits (turn off)
flags &= ~option4; // turn option 4 off
flags &= ~(option4 | option5); // turn options 4 and 5 off
- flip bit states
flags ^= option4; // flip option4 from on to off, or vice versa
flags ^= (option4 | option5); // flip options 4 and 5
输出不是直接写入的,它存储在缓冲区中,直到缓冲区被刷新。输出到文件或终端历来很慢(终端或控制台仍然很慢),逐个字符地写入是低效率的,写入一大块字节要有效得多。若 cerr 被缓冲,那么如果程序以非正常方式崩溃,您可能会将有用的调试信息卡在缓冲区中,而不是打印到 stderr。stdout 是行缓冲的,即在您编写换行符或显式刷新缓冲区之前,输出不会发送到操作系统。通常,std::endl 函数通过插入换行符并刷新流来工作。读取 stdcin 会刷新 stdcout ↩︎